Query based testing
Query based testing is a popular approach for automating data-driven testing. It consists of executing a query and comparing its actual outcome to an expected outcome.
- The actual outcome is be retrieved from the system under test during the test execution
- The expected outcome can be retrieved using different methods but will always derive or calculate what the actual outcome should be
It requires both functional and technical skills to be designed. Functional skills are needed to define the appropriate tests for the data. Technical skills are needed to write these tests in a technical format (SQL, data expressions, etc.). And it is this technical format that will allow automating the execution and evaluation.
Instead of manually testing a couple of data points, it becomes possible to easily scale the number of tests and execute them regularly. For this reason, this technique is used a lot for regression testing.
This approach can be applied to multiple situations:
- data platform testing (data warehouse, data hub, data integration layer, data lake, etc.)
- data migrations between all types of systems
- data quality assessments and monitoring
- etc.
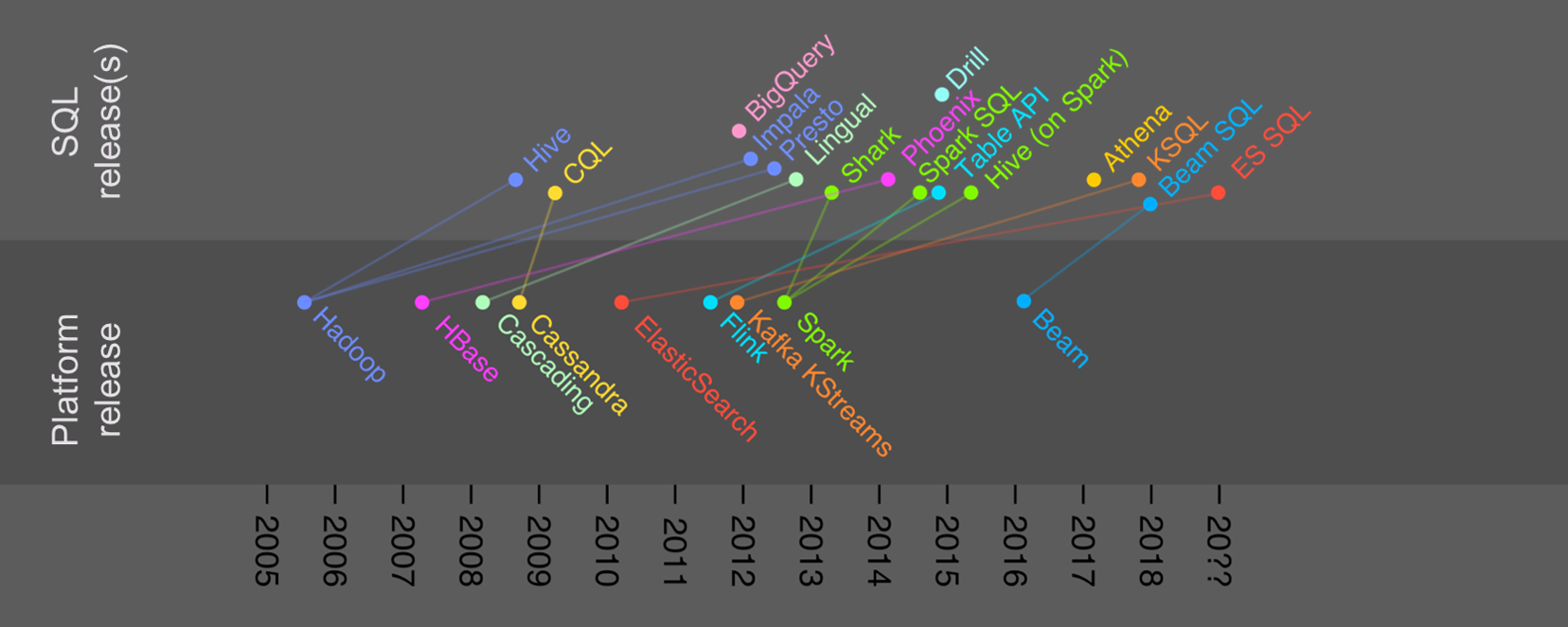
Are query based executions still relevant?
In the current context of big data solutions, one can wonder if query based execution are still relevant. They are still around and will continue to do so. After introduction of new technologies and patterns, at some point query based interfaces are added and maintained.
 source: https://conferences.oreilly.com/strata/strata-eu/public/schedule/detail/74048; authors: Elliot West, Jaydene Green
source: https://conferences.oreilly.com/strata/strata-eu/public/schedule/detail/74048; authors: Elliot West, Jaydene Green
we refer to query based interfaces rather that just SQL given the growth in other structure query languages across the data technology landscape.
Test examples
Examples of tests include:
- Verifying data structures (tables, columns, data types, etc.)
- Verifying source and target data sets when loading
- Verifying transformations of data are correclty performed
- Verifying data quality across the processing chaing
Techniques
Typical techniques for performing query based testing include:
- Use of minus queries directly on the system (comparing data sets)
- Verifying specific data related rules on a specific row or column
- Creating and comparing data structure (table, column, row) statistics
There is however not one technique that will be able to provide full coverage of data tests.
- minus queries will not detect duplicates (but data rules and statistics will)
- data rules will not detect completeness (but minus queries and statistics will)
- statistics will not detect correctness (but minus queries and data rules will)
Therefore, the best strategy is to design an approach that makes use of each technique where most effective but also efficient in setup and execution. Test automation is all about reducing risks through execution of a high number of test cases. Scale the right test cases and issues are more likely to be detected in an earlier phase.
In the context of query based testing, an end-to-end test script will help to keep the system that is tested under control:
- clean target tables
- load test data (that is stored in a test data store)
- perform query based tests on this controlled situations
- analyze issues In this scenario, the tests can be rerun many times after issue resolution or during a new release (as regression test) since the expected outcome is known. New test data and cases can be added easily allowing to grow the number of tests over time.
Use of minus queries
A minus query is a query that uses minus type operator (minus, except, intersect, etc.) to subtract one result from another giving the difference between both.
(add intersection diagram)
- If the actual outcome equals the expected outcome, then the test is successful.
- If the actual outcome and expected outcome are different, then the test is not successful. The differences can be used for analysis and issue resolution.
Minus queries compare two query results, input and output, allowing to verify inside a system if actual and expected outcome match:
- Selects, joins, group by’s and filters are applied to harmonize the data sets
- SQL expressions are used to perform lookups, defaulting and transformations
- The system’s query engine is used to perform the comparison.
The advantage is that the system will perform the work, not the testing application. The data is not duplicated. Only the test in the query set is performed. This is a disadvantage at the same time since that all data needs to be accessible by this same system.
This can result in different strategies if the data resides on different systems:
- Load input data into a temporary area of the system
- Make use of the systems federated query capabilities (assumes that this is available)
- Extract both input and output data to an external system to perform the verifications
- Make use of a distributed query engine (which typically decouples data storage from compute and provides some kind of virtualization method to decouple from the underlying systems)
Distributed query engine
(add presto)
- reduce resource need on the system being tested
Good practices
- The structure of both queries needs to be the same
- Columns: all columns presentin the actual outcome need to be present in the expected outcome as well
- Data types: data types need to be the same in both queries to be compared by the system
- It is advised to always include key columns to identify the exceptions easily
- Include other technical identifiers that help to ease the execution and follow-up processes (e.g. automation script)
- Document and inventorize queries, use naming conventions that structure them
- Use parameters to foster reuse where possible. By introducing parameter lists, the number of tests is grown by adding new values to the list (e.g. new tables or data flows)
- Split complex queries into multiple simple queries where possible
- Make sure to check the minus query in both directions to have
- all actual results that are not expected:
actual minus expected - all expected results that have not been found:
expected minus actual
- all actual results that are not expected:
- For performance reasons, a union can reduce execution time significantly:
(actual minus expected) union all (expected minus actual)
Verifying specific data related rules on a specific row or column
Creating and comparing data structure statistics
Typical examples here include:
- Data structures
- Number of rows
- Number of unique / distinct / null values in colums